
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- 틱택토
- 아키텍처 개선
- 프로그래머스
- 트랜잭션
- 최장증가부분수열
- Parametric Search
- synchronized
- Runtime data area
- MESI
- lis
- 세그멘테이션
- 자바
- 멀티 코어
- 표현 가능한 이진트리
- 이분탐색
- try-with-resource
- 캐시라인
- 이펙티브자바
- MVCC
- lv3
- multi-thread
- 멀티 프로세스
- OS
- java
- 멀티 스레드
- 실행과정
- try-catch-finally
- 메모리계층구조
- 방문길이
- 함께 자라기
- Today
- Total
siino's 개발톡
100만 건의 데이터로 Redis와 MySQL 조회 응답속도 비교하기 본문
이번 글에서는 프로젝트를 진행하면서 검색어 자동완성 기능을 구현했을 때 제가 고민했던 부분에 대해서 글을 써보겠습니다.
제가 개발했던 부분 중, 음식 이름 데이터를 사용해서 검색어 자동완성을 구현해야하는 작업이 있었는데요.
그때 고민해보았던 내용을 이번 기회에 다뤄볼까합니다.
DB와 redis에서 조회 성능의 차이가 얼마나 일어나는지 실험하기 위해서 각각의 데이터를 삽입하여 확인해보겠습니다.
(현재는 약 100만건의 음식 데이터가 DB와 redis에 저장되어 있는 상태입니다.)
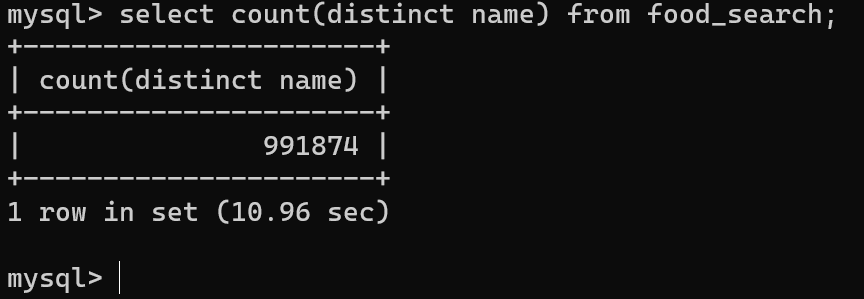
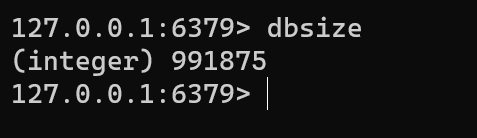
다양한 조건에 대해서 비교를 위해 api를 v1, v2, v3, v4로 나눠서 각각의 성능을 확인해보겠습니다.
v1 - Mysql full table scan
v2 - Mysql index 설정 후 full table scan
v3 - Mysql index 설정 후 limit 쿼리 활용
v4 - Redis에서 조회

v1/v2, v3, v4에 대한 세부 로직은 아래에서 확인해보겠습니다.
V1 - Table Full scan
먼저 v1과 v2에서 사용할 로직입니다.
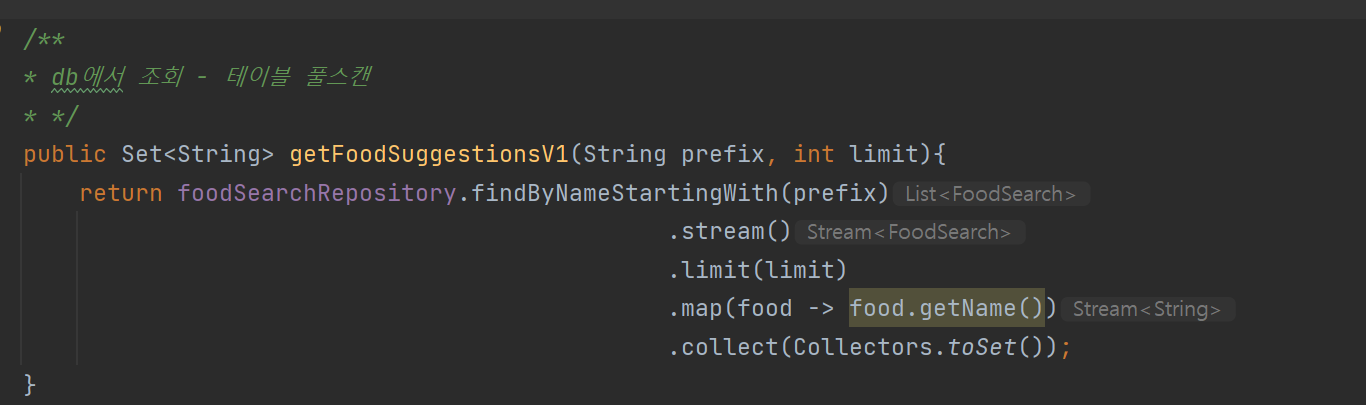
v1에서는 DB(mysql)에서 현재 검색어에 대한 like %prefix를 쿼리를 활용하여 table full scan후, 만족하는 행들을 전부 가져옵니다. 그 후에 limit을 통해 원하는 개수만 추출한 후 반환합니다.
이 v1에 대한 조회 성능을 간단하게 postman을 통해 확인해보겠습니다.
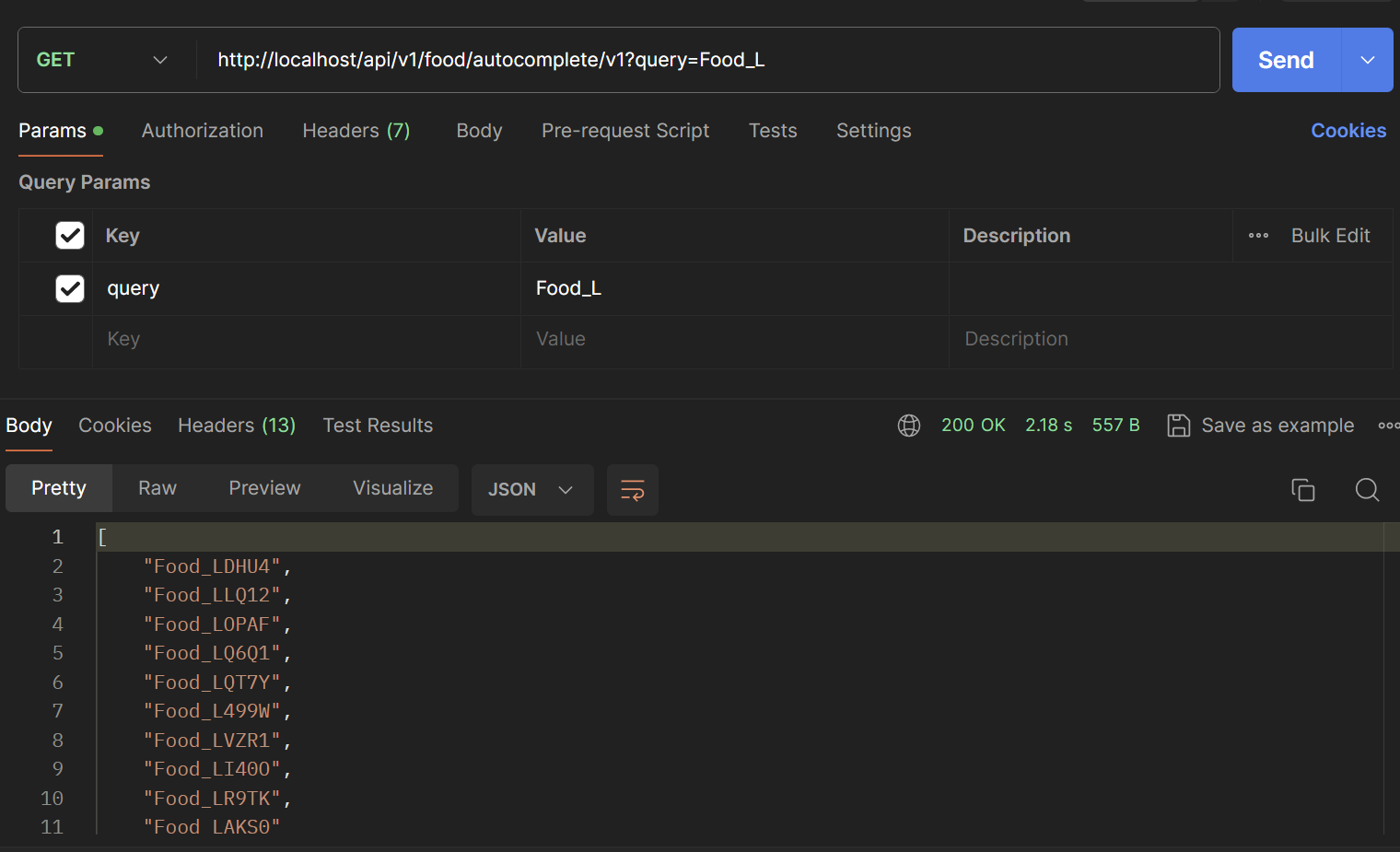
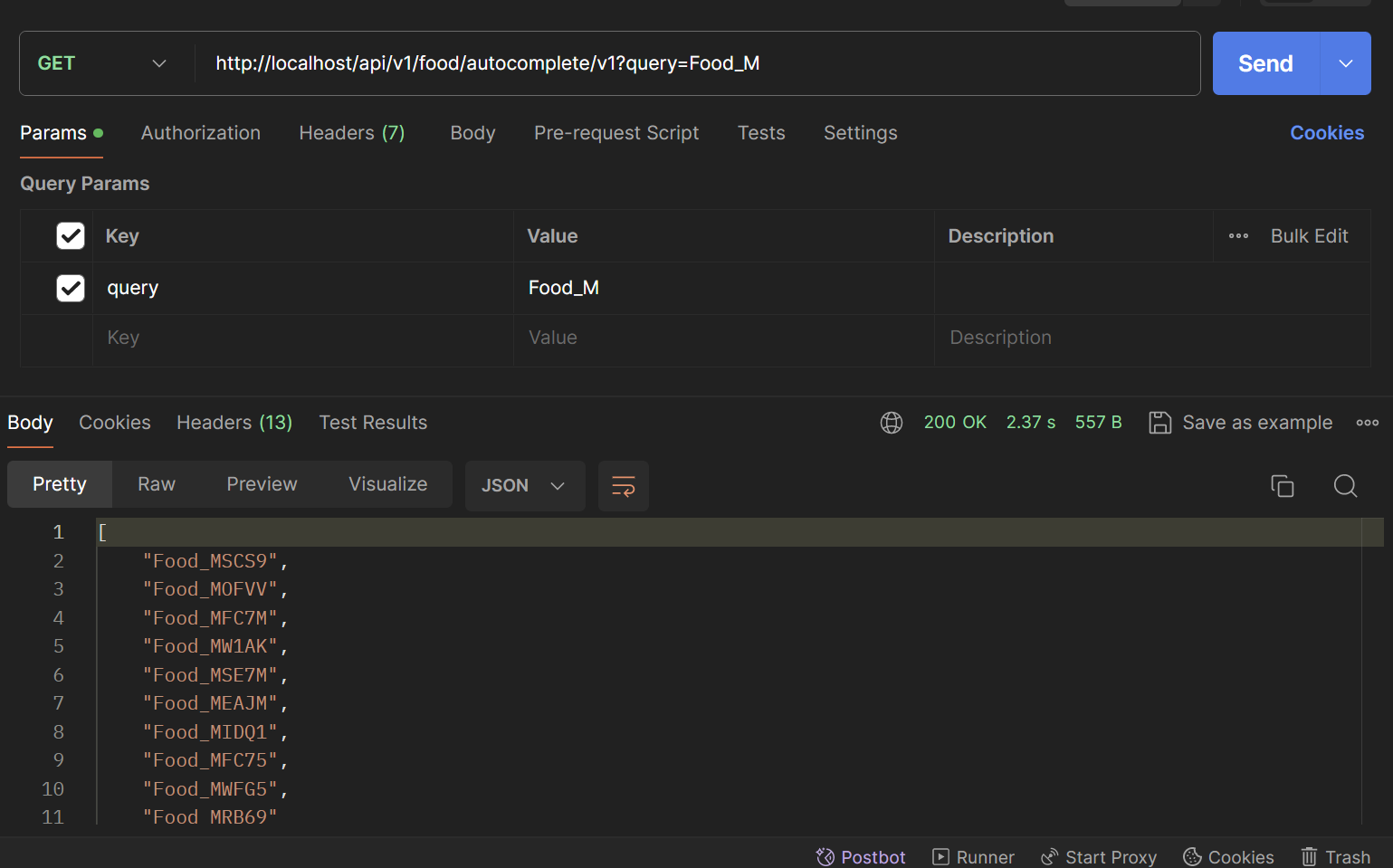
정말 어마어마한 시간이 걸립니다.
한 글자를 입력했을때 검색어 자동완성의 후보가 약 2초에 걸쳐 조회됩니다.
V2 - name 컬럼에 index 설정
다음으로는 mysql에 name 속성에 index를 설정해보겠습니다.

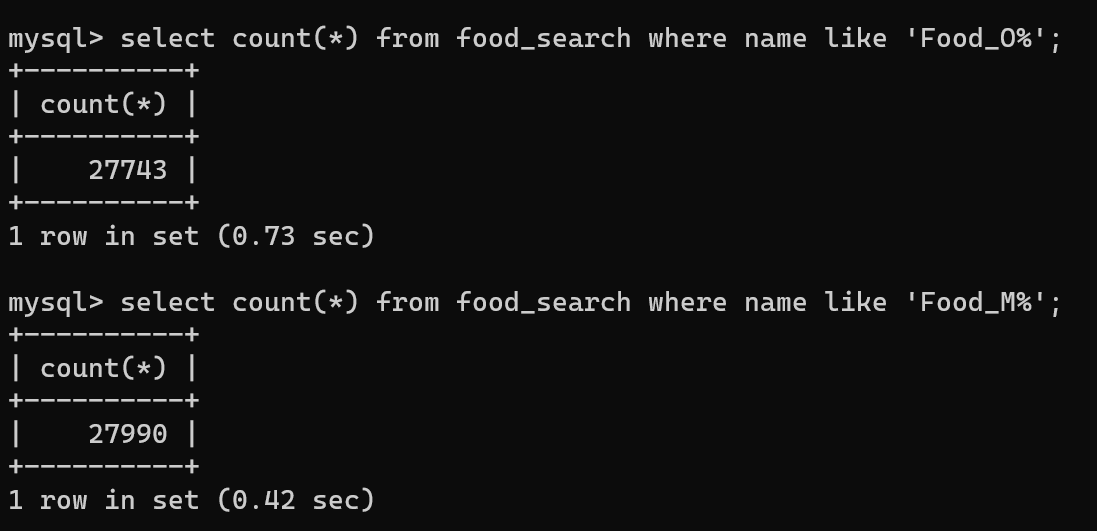

이렇게 index를 설정한 후에 테이블 full scan, 다시 v1 api를 확인해보겠습니다.(v1과 v2 api는 동일합니다.)
2.2s -> 1.8s정도까지 줄어든 모습입니다.
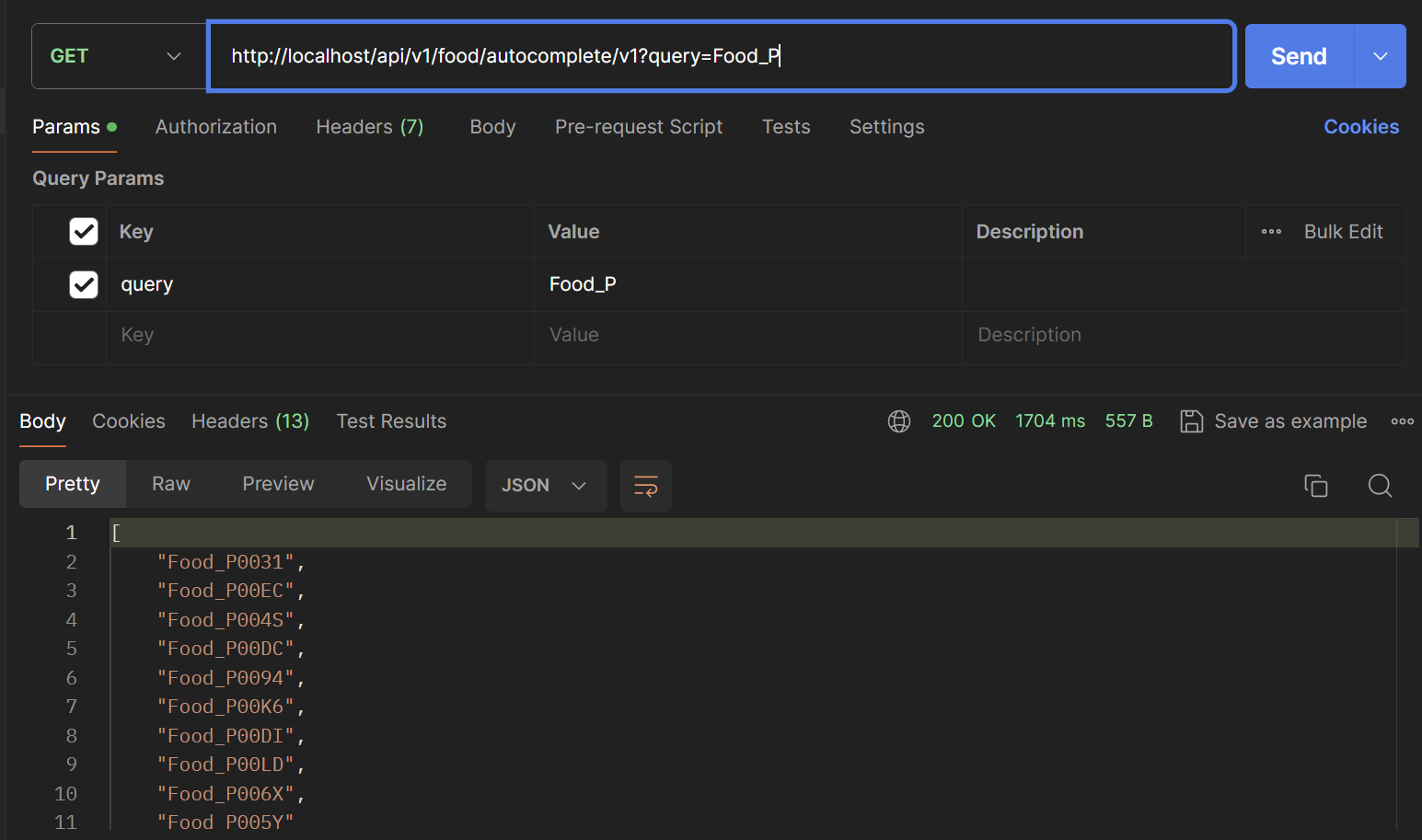
V3 - limit 쿼리 활용
이제는 조회시 limit쿼리를 포함해서 조회해보겠습니다.

Pageable 객체를 활용해서 limit쿼리를 수행할 수 있게 합니다.
Postman으로 성능을 확인해보겠습니다. (검색어는 Food_ZXC를 검색한다고 가정하겠습니다.)
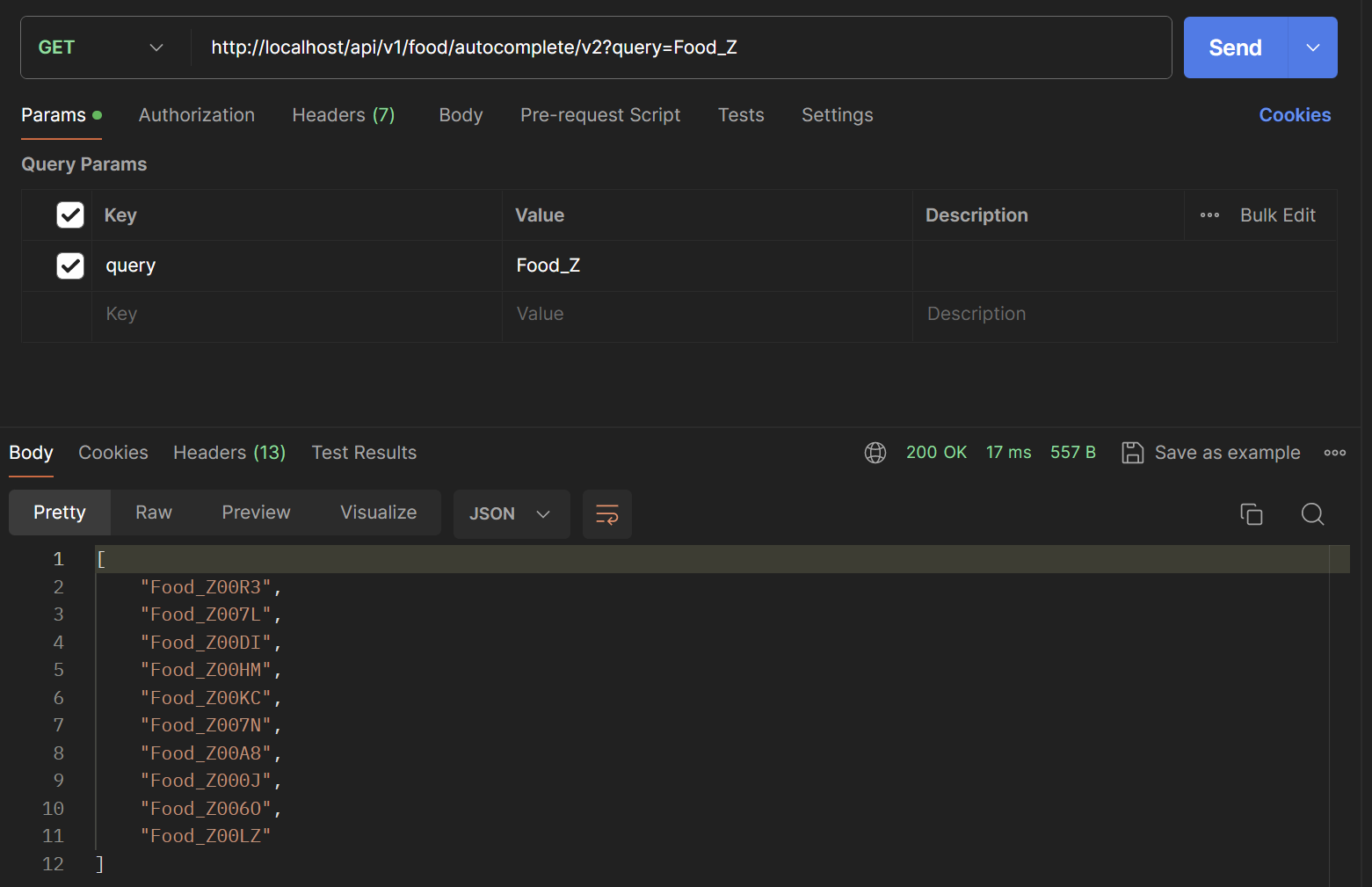
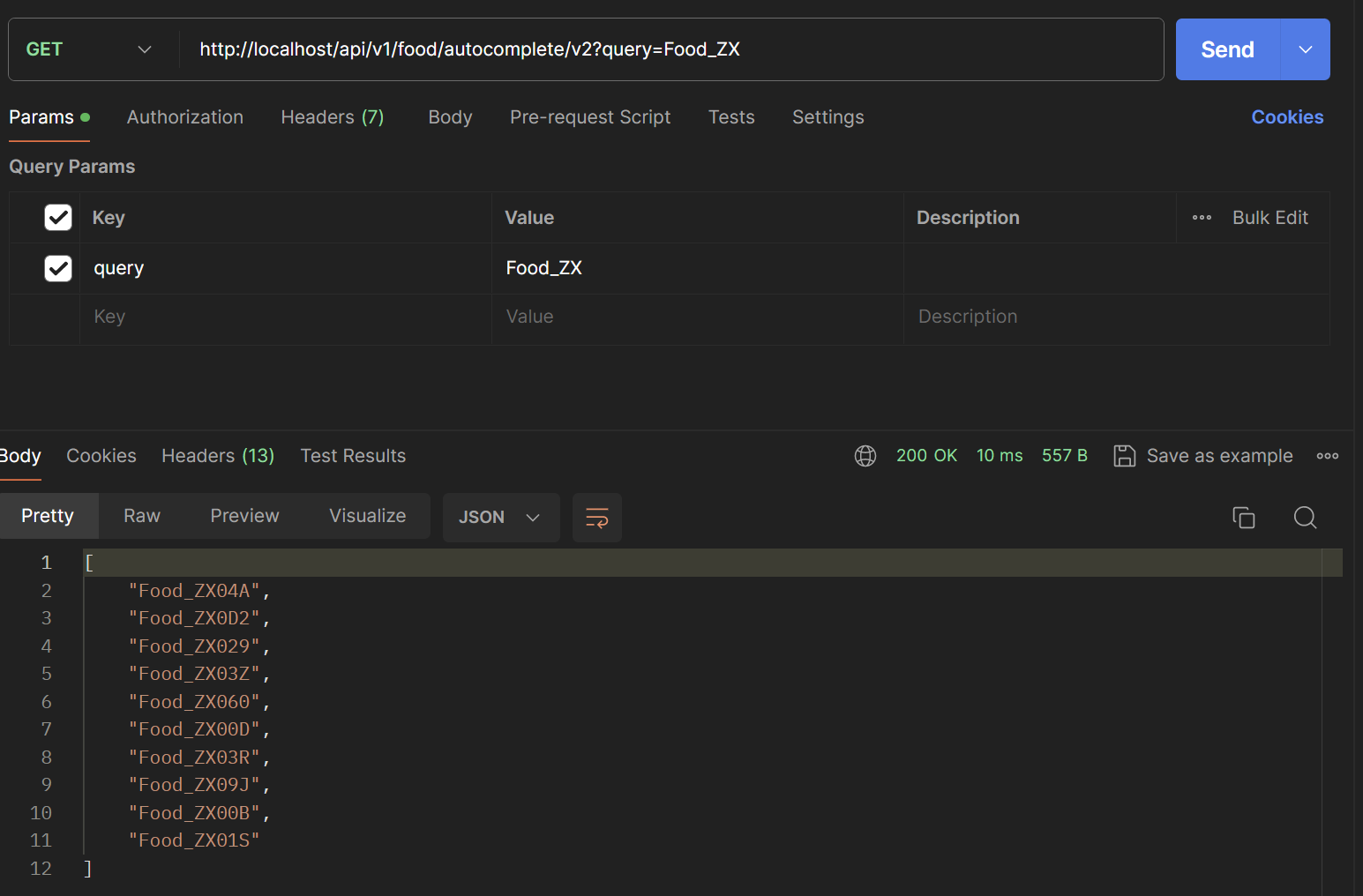
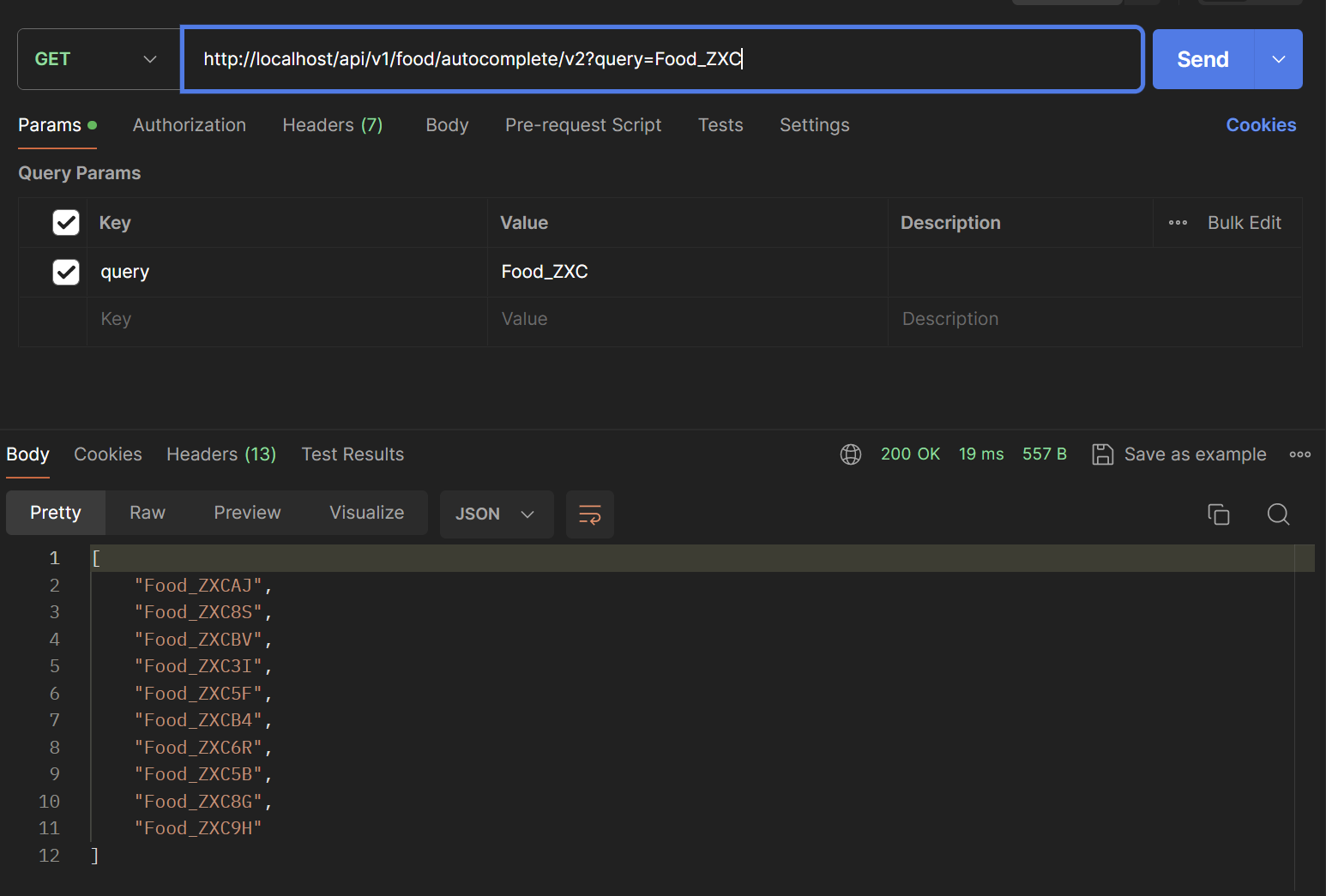
첫번째 글자 -> 17 ms
두번째 글자 -> 10 ms
세번째 글자 -> 19 ms
평균 15ms정도로 확인됩니다.
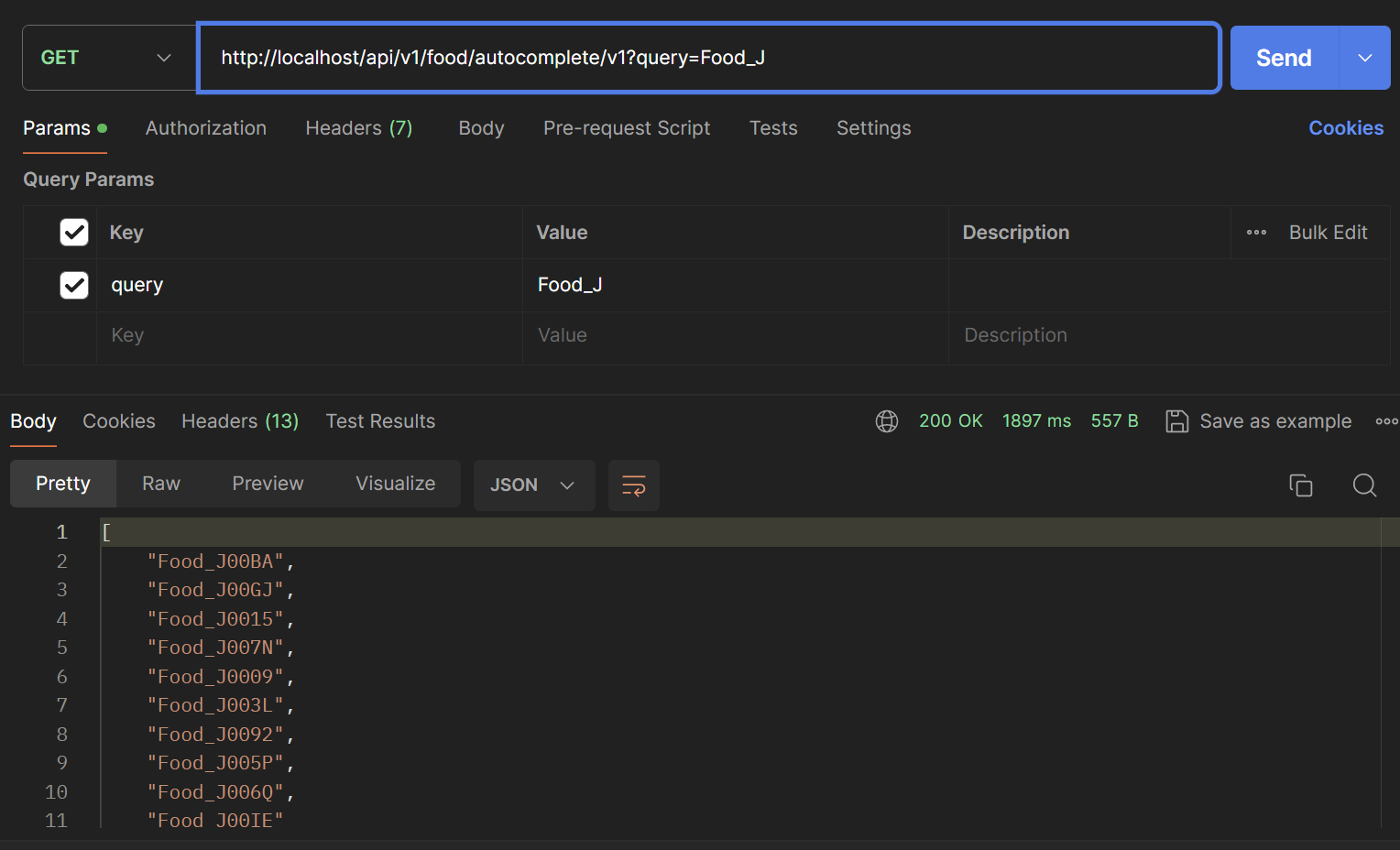
마지막 V4, Redis 조회

opsForZSet() 함수를 통해 range쿼리를 수행할 수 있고, sql의 like문과 유사한 쿼리를 만들 수 있습니다.
아래는 성능확인을 위한 postman입니다. (검색어는 v3와 동일하게 Food_ZXC를 검색한다고 가정하겠습니다.)
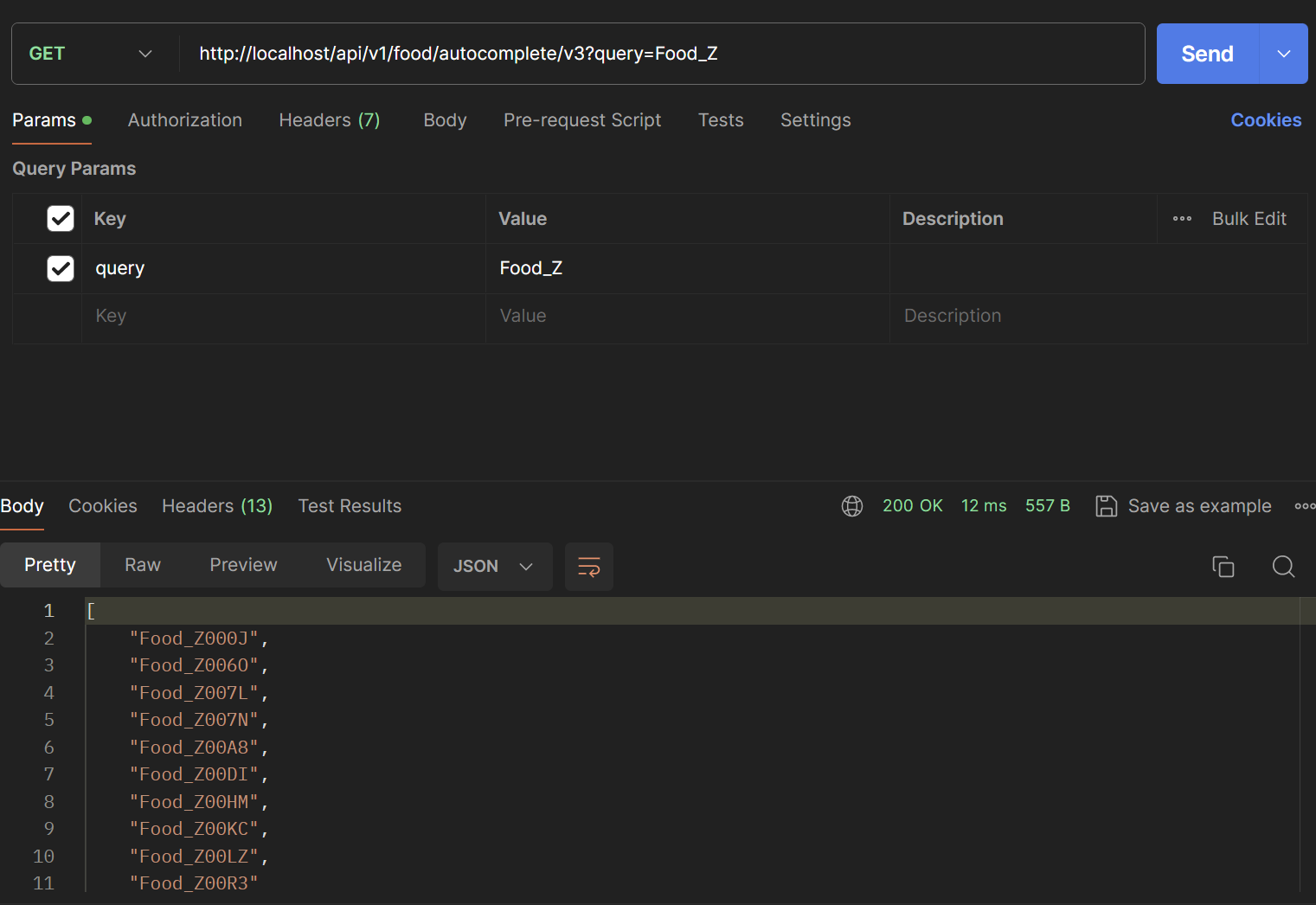
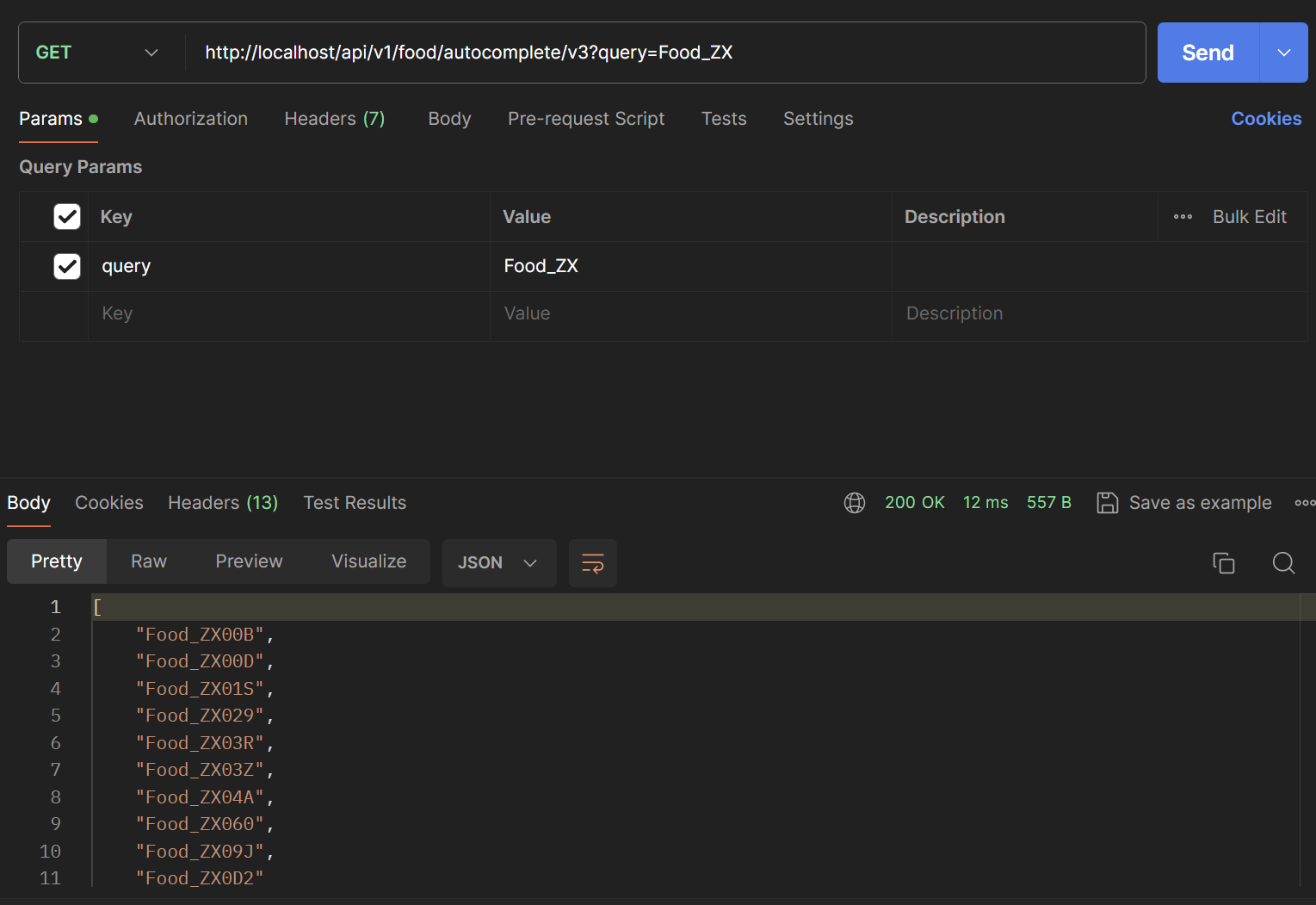

첫번째 글자 -> 12 ms
두번째 글자 -> 12 ms
세번째 글자 -> 9 ms
평균 11ms
정리하자면,
v1 - 2s (Mysql index 설정x, limit 쿼리 x)
v2 - 1.8s (Mysql index 설정o, limit 쿼리 x)
v3 - 15ms (Mysql index 설정o, limit 쿼리 o)
v4 - 11ms (Redis 조회, limit 쿼리 o)
확실히 데이터의 양이 많다보니, Table Full scan에 대한 Mysql 응답속도가 현저히 느렸고, limit 쿼리를 함께 수행했을 때 훨씬 나아진 것을 확인할 수 있었습니다.
Redis의 응답속도가 Mysql에서 검색을 위한 음식 이름 컬럼에 index를 설정하고 limit쿼리로 측정한 응답속도와 크게 차이가 안난다고 생각하실 수 있겠지만, 응답시간 15ms에서 11ms로 4ms 검색 속도 단축은 기존 응답시간 대비 26%의 성능 상승이라고도 생각할 수 있습니다.
v3, v4에 대해서..
Postman 으로 측정했을 때, 명확한 비교가 안된다고 생각하여 부하테스트 툴인 locust를 실제로 돌려보았습니다.
peak User수 1명부터 100명까지 1씩 증가
MYSQL (인덱스 적용) : 38403 요청 처리, 평균 147.19ms

Redis : 53264요청 처리, 평균 91.8ms

약 38%의 성능 향상.
추가로 지금은 100명의 요청에 대해 측정을 했지만 1000명의 사용자가 있다고 가정한다면 전체적으로 0.5초의 시간이 단축되는 것이고, 이는 서비스 관점에서 처리량(throughput)에 중대한 영향을 끼칠 수 있는 시간이라고 생각합니다.
Google 연구에 따르면, 로딩 시간이 1초 지연될 때마다 페이지 이탈률이 7% 증가한다고 합니다.
그리고 현재는 단순히 성능 비교를 위해 redis의 사전순 정렬을 통해 range query를 수행했지만 자주 검색되는 검색어의 score를 높이고 해당 우선순위를 높이는 등의 다양한 작업을 redis에서 수행할 수 있습니다.
이와 같은 이유로 프로젝트 시, 검색어 자동완성 기능에 대한 구현으로 저는 Redis를 도입하게 되었답니다.
'프로젝트' 카테고리의 다른 글
| 프로젝트 아키텍처 리팩토링 (+비동기 통신) (0) | 2024.03.04 |
|---|---|
| Redis 캐싱 전략 개선 및 스케줄링 (0) | 2024.02.20 |

